Lakehouse data bevragen vanuit een Warehouse in Microsoft Fabric
Microsoft Fabric is de volgende generatie analytics platform van Microsoft. Het biedt onder andere data lakehouse en data warehouse architecturen met ondersteuning voor SPARK en T-SQL.
In deze blog leg ik kort uit hoe je data in een Fabric Lakehouse kunt bevragen vanuit een Fabric Warehouse met T-SQL zonder data te kopiëren.
Om dit te kunnen doen heb je twee objecten nodig binnen jouw Fabric werkplek:
- Lakehouse
- Warehouse
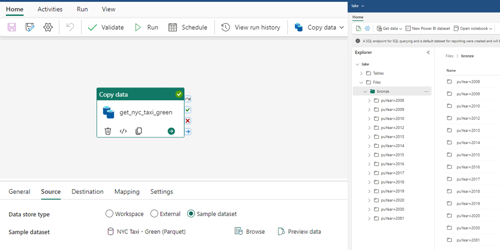
In mijn Fabric Lake heb ik voorbeeld data geladen via een Fabric pipeline “p_nyc_data”.
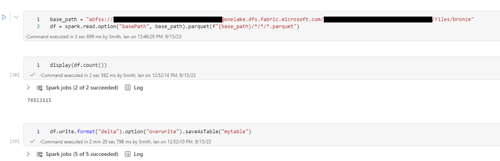
Vervolgens heb ik met een Fabric notebook de data in een Delta tabel geplaatst. Niet de meest toekomstvast code ;-), maar voor dit voorbeeld voldoende.
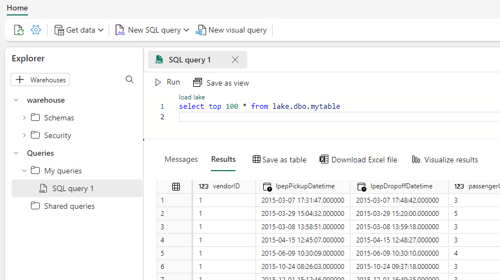
Nu kan ik vanuit mijn Fabric Warehouse deze delta tabel bevragen met T-SQL door in mijn query ook de naam van mijn lakehouse op te nemen; [lakehouse].[schema].[table]
Je kunt dit in elke SQL-query gebruiken zoals je ook tabellen in je Warehouse zou bevragen, zoals SELECT, JOIN, GROUP BY, enzovoort. Bijvoorbeeld, als je je Warehouse-klantentabel wilt koppelen aan je Lakehouse-sales-tabel en het totale orderbedrag per klant wilt krijgen, kun je de volgende T-SQL-instructie gebruiken:
SELECT c.customer_id, c.customer_name, SUM(o.amount) AS total_amount
FROM dim_customers c JOIN lake.dbo.sales_lines o
ON c.customer_id = o.customer_id
GROUP BY c.customer_id, c.customer_name
ORDER BY total_amount ASC;
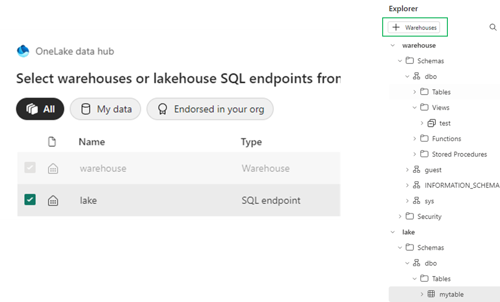
Vanuit de “Explorer” kan je ook de SQL-endpoint van jouw lakehouse selecteren. Dit laat dan de beschikbare tabellen zien binnen in de “Explorer” zodat verkenning nog makkelijker gaat.
Conclusie
Met Fabric kun je data bevragen en combineren tussen lake en warehouses zonder dat je data hoeft te kopiëren. Combineer dit ook met de mogelijkheden van shortcuts (OneLake shortcuts - Microsoft Fabric | Microsoft Learn) en duplicatie van data kan zo maar een ding van het verleden worden.
Dit creëert ook nieuwe mogelijkheden voor bestaande datateams. Power BI Consultants kunnen bijvoorbeeld warehouses makkelijker en sneller inrichten met stermodellen op basis van data uit verschillende lakehouse’s klaargezet door data engineers.

