Wat is een data lake?
De data services schieten anno 2022 als paddenstoelen uit de grond. Als je tien jaar geleden wist wat een datawarehouse was dan had je voldoende achtergrond om te weten waar je terecht kon voor data vraagstukken binnen een organisatie. Al snel werd deze term de afgelopen jaren gevolgd door trendy termen als data lake, dataplatform en data hub. Maar wat betekenen al deze termen nu eigenlijk en hoe verhouden ze zich tot elkaar?
In deze editie van de serie #adatawhat kijk ik naar de term data lake.
Inleiding
Ruim twaalf jaar geleden, in oktober 2010, was het James Dixon die de term data lake voor het eerst introduceerde. Inmiddels is de term breed gedragen, hebben de grote cloud providers hun eigen oplossingen geïntroduceerd, en maken steeds meer organisaties gebruik van zo'n data lake. Maar wat is een data lake eigenlijk?
Het begrip data lake is voor velen nog ongrijpbaar. Hoe ziet het er uit, wat kan ik er mee en is het iets wat iedere organisatie zou moeten hebben? Met dit artikel hoop ik je meer inzicht te geven in wat een data lake in basis is en welke rol het kan spelen in een organisatie.
Historie
Al rond 1970 was het de bekende Bill Inmon die begon over het concept data warehousing om data uit operationele systemen te verzamelen ten behoeve van data gedreven beslissingen, een term die we tegenwoordig nog steeds veel terug zien komen. De afgelopen decennia heeft digitalisering een enorme vlucht genomen en zijn we steeds meer data gaan verzamelen.
Naast gestructureerde data geldt dat er ook sprake is van een enorme groei in ongestructureerde data, zoals video's, spraakbestanden, plaatjes en tekstbestanden. Een data warehouse kenmerkt zich door een verzameling van gestructureerde data. De toename van ongestructureerde data vraagt zodoende om een nieuwe technologie om ook deze data te kunnen opslaan en analyseren. De komst van het data lake was een logische vervolgstap.
Dat de komst van het data lake parallel loopt aan de opkomst van de cloud lijkt geen toeval. Dankzij het ontstaan van het data lake is het mogelijk geworden om big data (lees: grote hoeveelheden gestructureerde en ongestructureerde data) op één centrale locatie te verzamelen. Dit vraagt om grote opslagcapaciteit, waarbij de hoeveelheid data exponentieel kan groeien. De eenvoudig schaalbare opslagmogelijkheden in de cloud zorgen naast relatief lage opslagkosten ook voor een schaalbare oplossing om gecontroleerd te kunnen groeien in het opslaan van data. Het data lake was geboren.
Wat is een data lake?
Maar wat is een data lake dan eigenlijk? In basis is een data lake een centrale locatie voor de opslag van zowel gestructureerde als ongestructureerde data. In een data lake wordt doorgaans ruwe data opgeslagen, waarmee wordt bedoeld dat de data wordt opgeslagen zoals het uit de bron afkomstig is. Naast data uit applicaties wordt er vaak ook data opgeslagen van bijvoorbeeld sensoren (IoT) en andere nieuw type databronnen. Waar een data warehouse voornamelijk wordt gebruikt door business analisten en voor managementrapportages, geldt voor een data lake een bredere groep aan gebruikers. Zeker voor data scientists is het data lake van onschatbare waarde. Ruwe data is beschikbaar, waarmee het voor data scientists mogelijk is om op onbewerkte data algoritmen los te laten, de datasets links en rechts wat bij te schaven door data op te schonen en te filteren en er vervolgens waardevolle voorspellingen mee te genereren.
Omdat een data lake voornamelijk ruwe data is opgeslagen kan de kwaliteit van de data enorm variëren. Gebruikers van data uit een data lake dienen dan ook sterk rekening te houden met de situatie dat data nog opgeschoond en gefilterd moet worden voor waardevolle analyses. Het proces om vanuit een data lake tot waardevolle data te komen voor verdere analyses kan zodoende complex en langdurig zijn.
Gebruik van een data lake
Het is verstandig goed na te denken over de inrichting van een data lake. Een goede inrichting vereenvoudigd het gebruik er van. Het is belangrijk om onder andere rekening te houden met autorisaties. Vermoedelijk mogen niet alle gebruikers van je data lake gebruik maken van dezelfde data. Ook dient stil te worden gestaan bij wet- en regelgeving, zoals de GDPR. Het opslaan van privacygevoelige data in een data lake vraagt ook om een beleid hoe om te gaan met deze data.
Een data lake is zeker geen alternatief voor een data warehouse. Het fungeert wel vaak als een alternatief voor de staging laag binnen een data warehouse. De staging laag in een datawarehouse kenmerkt zich eveneens door het opslaan van ruwe data, om van daaruit de benodigde transformaties in het data warehouse toe te passen. Met het inpassen van een data lake binnen het data landschap van een organisatie kan deze in het geval van een data warehouse deze rol van een staging laag dus in veel gevallen op zich nemen.
Afhankelijk van het type gebruiker zal deze gebruik maken van of het data warehouse of het data lake. Voor sommige rollen is een combinatie van beide eveneens interessant! Hieronder een eenvoudig overzicht van type gebruikers die vaak worden onderkent binnen een organisatie. Ieder type gebruiker prikt in op een andere laag binnen het data landschap van de organisatie.

Met de aanleg van een data lake is een organisatie vele malen schaalbaarder dan met de staging laag uit de data warehouse methodiek. Het grote voordeel van een data lake is tevens dat er met veel meer toepassingen en talen gecommuniceerd kan worden. Oplossingen als Databricks bieden de mogelijkheid om data vanuit een data lake rechtstreeks in te lezen in een analyse platform om van daaruit met bijvoorbeeld Python of SQL de data te bevragen en analyseren.
Een data lake is zeker geen magische oplossing voor al je data vraagstukken. Zonder een gedegen beleid op te stellen voor het gebruik van je data lake is de kans groot dat gebruikers verdrinken. Als tegenhanger van een data lake wordt dan ook wel gesproken van een data swamp.
Om een data swamp te voorkomen is het belangrijk om na te denken hoe gebruikers van de data uit je data lake deze in de juiste context kunnen plaatsen. Het bijhouden van metadata is dan ook sterk aan te bevelen.
Data warehouse of Data lake?
Steeds vaker krijg ik de vraag of een data warehouse nog wel de beste oplossing is voor organisaties om inzicht te krijgen in data. Een data lake wordt geregeld als toverwoord gezien om alle data te verzamelen van daaruit te rapporteren. Waar vervolgens aan voorbij wordt gegaan is dat een data lake ruwe data bevat en daarmee wellicht nog opgeschoond en getransformeerd moet worden om waardevolle cijfers voor bijvoorbeeld managementrapportages te presenteren. Tevens ontbreken de normaal in een data warehouse vastgelegde business rules om tot definities van bepaalde KPI's te komen. Dat maakt een data lake in basis geen alternatief voor een data warehouse.
Steeds meer organisaties richten een data lake in. Dat kan op vele verschillende manieren, maar het concept data lake wordt doorgaans gebruikt om een centrale plek te creëren om zoveel als mogelijk data te verzamelen. Organisaties die al een data warehouse hebben gebruiken steeds vaker het data lake als bron voor hun data warehouse. Het data lake dient daarmee als soort van staging area, welke aanvullend gebruikt kan worden door nieuwe rollen in de organisatie zoals een data scientist.
Vaak wordt een data lake al aangelegd voor er een specifieke casus is benoemd. Het is de rol van data die steeds belangrijker wordt voor organisaties die data gedreven willen werken of optimale service willen aanbieden aan hun medewerkers en klanten. Wanneer het data lake eenmaal is opgezet kunnen verschillende typen data consumenten er gebruik van maken. Voor de klassieke rapportages en informatiebehoeften blijft de noodzaak voor een data warehouse vaak bestaan. Het data lake wordt vaak geïmplementeerd binnen de bestaande architectuur. Voor organisaties die hun data warehouse omgeving nog niet naar de cloud hebben gemigreerd is het opzetten van een data lake vaak de eerste stap in de transitie naar de cloud.
Hieronder de mogelijke inrichting van een organisatie met enkel een data warehouse (links) versus een organisatie met een data lake en een data warehouse (rechts).
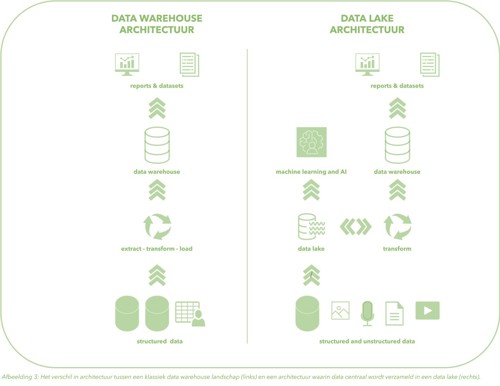
Concluderend kunnen we zeggen dat er geen one-size-fits-all is. Voor vele organisaties blijft een data warehouse voorlopig nog heilig. De komende jaren zal het werken met en op basis van data verder versnellen. Het is zodoende wel raadzaam na te denken of en hoe een data lake een plaats verdient binnen het data landschap van de organisatie.
Een data lake inrichten
Het inrichten van een data lake kan op verschillende manieren. Alle grote cloud providers bieden een data lake oplossing aan. De meest bekende is wellicht Azure Data Lake, welke in 2016 voor het eerst ter beschikking werd gesteld binnen het Azure Cloud platform van Microsoft. Bij Google is het Google BigQuery wat officieel te boek staat als data warehouse oplossing. Echter omvat deze service van Google overeenkomsten met onder andere de Azure Data Lake service van Microsoft. Bij Amazon is de AWS Lake Formation in het leven geroepen om een data lake aan te leggen.
De exponentiële groei van data die we nu doormaken zal nog wel enige tijd aanhouden. De behoefte om nog meer vernieuwingen rondom deze services is zodoende te verwachten. Als de trend zich doorzet zal het nog laagdrempeliger worden om data op te slaan, te consumeren en te delen.
Is een data lake voor mij waardevol?
Het hebben van een data lake is geen doel op zich. Er zijn talloze organisaties te bedenken waar een data lake niet per definitie benodigd is om in de behoeften te voorzien. Organisaties met kleine hoeveelheden data kunnen de stap data lake wellicht overslaan en direct rapporteren en analyseren via bijvoorbeeld visualisatietools als Microsoft Power BI.
Zeker voor organisaties met een versnipperd data landschap, bijvoorbeeld door het gebruik van veel SAAS-oplossingen (Software-as-a-Service) kan het verkrijgen van inzichten en het doen van analyses en zoeken van verbanden een ingewikkeld proces zijn. In zulke situaties biedt een data lake toegevoegde waarde als punt waar alle data samenkomt om van daaruit verdere analyses te kunnen doen. Ook bij organisaties met grote hoeveelheden data (big data) kan een data lake een toegevoegde waarde bieden.
De benodigde capaciteit voor het opslaan als het raadplegen van de data is met de cloud-diensten van tegenwoordig schaalbaar. Het voordeel hiervan is dat de gedachte 'start klein, denk groot' kan worden toegepast. De initiële opzet van een data lake hoeft geen grote kostenpost te zijn. Het kan wel een waardevolle toevoeging zijn in de volgende stap van je data platform!
Tekst: Bob Woets

