Wat is het verschil tussen Data Lakehouse Data Warehouse en SQL endpoint in Microsoft Fabric?
Microsoft heeft tijdens de Build 2023 conferentie 'Fabric' geïntroduceerd. Fabric voegt de data engineering, machine learning en Power BI ervaring samen onder één noemer. Fabric introduceert, net als Synapse Analytics, twee “manieren” van het opslaan en analyseren van data:
- Data Lakehouse
- Data Warehouse
Beide zijn te creëren vanuit Microsoft Fabric. Dan is er ook nog de SQL Endpoint. Maar wat is nou het verschil tussen Data Lakehouse, Data Warehouse en SQL endpoint in Microsoft Fabric? Wanneer kies je voor een lakehouse en wanneer voor een warehouse? Om hier antwoord op te geven zullen we eerst moeten begrijpen wat elke service doet en kan.
Waar het allemaal begon, data warehousing
Data warehousing ontstond als een concept en technologie in de jaren 80. Het ontstond als reactie op de groeiende behoefte van organisaties om grote hoeveelheden gestructureerde data die gegenereerd werden door verschillende systemen, effectief te analyseren. Termen als ETL, OLAP en Dimensioneel modelleren zijn daar ontstaan. Data warehousing maakt gebruik van de SQL-taal om gegevens te analyseren en te bewerken.
Het ontstaan van de data lakehouse
Terwijl datawarehousing zich richt op het werken met gestructureerde data, hebben data lakehouses als doel zowel gestructureerde als ongestructureerde data vast te leggen en op te slaan zonder de noodzaak van uitgebreide voorbewerking of modellering vooraf. Dit zorgt voor meer flexibiliteit en wendbaarheid bij het analyseren en verkennen van data. Een data lakehouse werkt voornamelijk met pySpark (python) om gegevens te bewerken.
SQL Endpoint?
Microsoft Fabric introduceert een derde service genaamd “SQL Endpoint”. Vanuit een Lakehouse kan je deze rechtsboven selecteren.
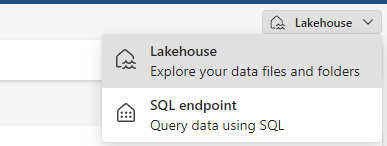
Dit is het meest te vergelijken met SQL serverless pool in Azure Synapse Analytics. Het grootste verschil is dat de tabellen in een Lakehouse direct herkenbaar zijn vanuit de SQL Endpoint. Je hoeft dus niet eerst met OPENROWSET een query te definiëren, zoals je dat Azure Synapse Analytics binnen de SQL Serverless Pool wel moet doen.

Vanuit de SQL Endpoint kan je tabellen direct bevragen.
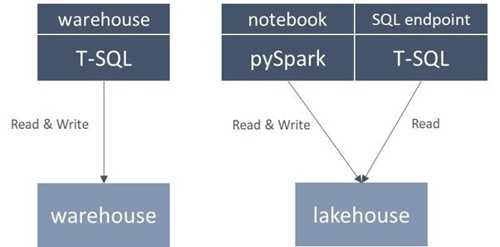
Microsoft Fabric biedt dus beide services aan en elk zijn te bevragen en te bewerken met twee “categorie” talen; T-SQL en Spark (PySpark, Scala, Spark SQL en R).
De service (data warehouse, lakehouse of SQL Endpoint) bepaalt welke taal waar gebruikt kan worden. Onderstaand figuur geeft weer welke taal in welk scenario gebruikt kan worden. Merk op dat hier pySpark ook de overige Spark talen representeert.
Conclusie
Microsoft Fabric maakt het mogelijk om een lakehouse zowel met pySpark als T-SQL te bevragen. Weten wanneer je welke taal inzet is hier belangrijk in. Een lakehouse bewerken doe je nog steeds met talen zoals PySpark vanuit een notebook, echter is het bevragen nu ook mogelijk van T-SQL.
Meer informatie is hier terug te vinden:
Ook aan de slag met Fabric? Join the team!
Bekijk onze vacatures

