Data partitioning met Power BI & Dataflows
Tijdens één van onze projecten liepen we tegen de volgende uitdaging aan; voor een klant moesten wij transactiedata ophalen via een API met Power BI voor enkele rapporten. We liepen tegen een aantal uitdagingen aan:
- Elke keer als wij via Power BI meer dan een jaar aan data wilden ophalen, kneep de API de toevoer en moesten we 24 uur wachten.
- Direct contact met de leverancier van de API was helaas niet mogelijk.
- Reeds ingelezen data uit het verleden moest opnieuw opgehaald kunnen worden vanwege correcties op de data in het verleden.
- We hadden geen beschikking over XLMA endpoint.
In deze blog leggen we uit wat we hebben geprobeerd, welke uitdaging we zijn tegengekomen en hoe we deze uitdagingen het hoofd hebben geboden.
Het idee: Data partitioning met Power Query
Een mogelijke oplossing is het opdelen van de transactie dataset in kleinere delen zodat elke deel individueel te verversen is. Binnen Power BI beschikken we over de mogelijkheid om data te transformeren. De plek waar we dat doen heet technisch “Power Query Editor”.
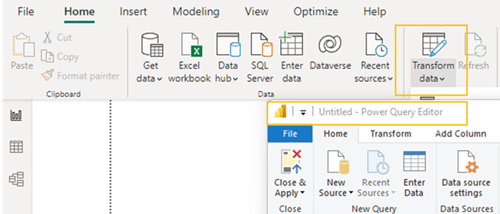
Met Power Query Editor definiëren we een specifieke query voor elke partitie. Elke query bevat dus, middels een gedefinieerde filter, een subset van de totale transactie dataset.
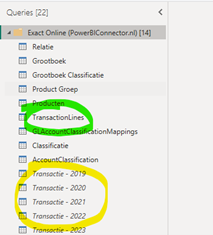
In dit voorbeeld hebben wij een query gedefinieerd per jaar; “Transactie – 2019”, “Transactie – 2020” etc. Voor elk van deze query’s hebben wij de optie “Include in report refresh” en “Enable load” uitgezet, exclusief het actieve jaar. Dit betekent dat de data eenmalig wordt geladen maar niet meer wordt ververst wanneer je er vanuit het rapport de opdracht toe geeft.
Een laatste query (in dit voorbeeld genaamd “TransactionLines”) bevat de “merge” (samenvoeging) van elke query.
![]()
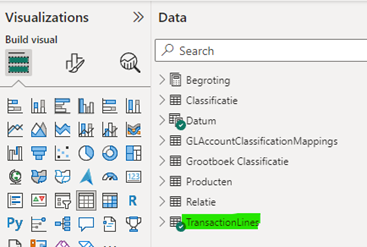
De query “TransactionLines” acteert voor de eindrapporten als één tabel, maar in werkelijkheid is dit de samenvoeging van verschillende onderliggende query’s.
Het probleem: the service says no
De uitdaging is echter dat de verwachte werking niet opgaat zodra je het model publiceert naar de Power BI service. Daar ververst Power BI alle query’s waarnaar gerefereerd wordt. De Microsoft community heeft hier al een melding van gedaan: Microsoft Idea (powerbi.com).
Een oplossing: Power BI Dataflows to the rescue
Power Query Editor is ook beschikbaar binnen de Power BI service als SAAS oplossing onder de naam Dataflow.
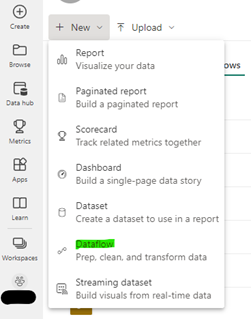
De verschillende gedefinieerde query’s van elk transactie jaar hebben we verplaatst naar de Power BI service als een Dataflow:
Vervolgens hebben we vanuit de Power BI desktopomgeving een verbinding gemaakt naar elk van deze Dataflow’s:
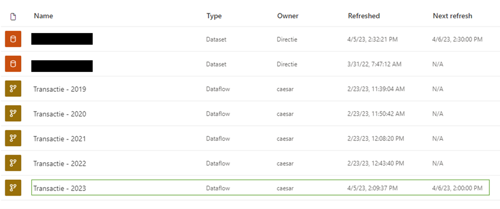
Dit resulteert in een op het oog hetzelfde resultaat. Maar, in plaats van dat elke query een lokale definitie bevat, verwijst deze naar een aparte dataflow in de Power BI service:

In de Power BI service bepalen we vervolgens wat automatisch wordt ververst en wat niet.
Conclusie
We hebben gezien hoe je met Power Query Editor een grote data set kan opdelen in kleinere delen door hier individuele query’s voor aan te maken, elk representeert dan bijvoorbeeld een jaar aan data.
Met de “merge” expressie hebben we gezien hoe je deze verschillende query’s kan laten samenvoegen in één “hoofd” tabel. Door elk van deze query’s te maken binnen Power BI Dataflow’s creëer je een oplossing waarbij je zelf kan bepalen welke partities je wanneer wilt verversen.
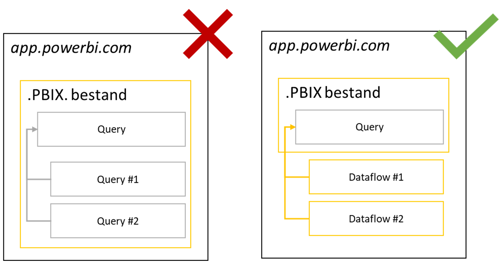
Een nadeel aan deze benadering is echter dat je handmatig de partities moet aanmaken en beheren. Bij elk nieuw jaar dat er bij komt moet je zelf een partitie toevoegen.
Met speciale dank aan onze collega Jessy Schurink, hij kwam op het idee om Power BI dataflows in te zetten voor deze uitdaging.
