UDF’s in Power BI. Eén keer schrijven, veel gebruiken
UDF’s? Unidentified flying... Nee, ze bestaan écht al een tijdje, zij het in Preview. Maar wat zijn dat voor een dingen? Waarom zou je ze gebruiken? En als je ze zou willen gebruiken, hoe dan? Is er iets dat je in de smiezen moet hebben om ze goed te gebruiken. Spoiler alert: jawel! En heeft het toevallig met die vermaledijde filtercontext te maken? Zeker. Het blijft DAX. 😊
Wat zijn UDF's?
UDF’s: User Defined Functions. Wat zijn het? Stoelriemen vast: Functies die je zelf maakt. Bijgekomen? Sorry. Meer of minder kan ik er niet van maken. Iedere Power BI-ontwikkelaar gebruikt functies als CALCULATE, SUM, REMOVEFILTERS, noem maar op. Nu is daar dus de nieuwe FUNCTION- functie bij gekomen. Wat ie precies doet, bepaal jij.
Waarom zou je UDF's gebruiken?
User Defined Functions gebruik je wanneer dezelfde berekening meerdere keren voorkomt. Twee voorbeelden:
1. Conditional formatting voor KPI-cards
Je hebt een trits van tien Card visuals met KPI’s voor ‘variance’ (verschil tussen werkelijke omzet met budget, met laatste bijgewerkte schatting, met vorig jaar, je kent het wel). Je wilt de cijfers duiden door deze een kleur te geven: rood is slecht, groen is goed en grijs is neutraal. Wanneer de kleur die je wilt geven afhankelijk is van iets complexere logica dan je kunt ondervangen met conditionele opmaakmogelijkheden op basis van een simpele ‘rule’ (De variance is pas groen als de gemiddelde omzetgroei over de afgelopen drie maanden hoger is dan 10%), dan regel je de kleuropmaak via een field value die je zelf in een measure definieert.
Op zich geen probleem, alleen, dat moet je dan wel tien keer doen. En wat als de huisstijl verandert en de kleurcode voor rood verandert? Dan kun je wéér aan de gang. Met een UDF heb je één measure voor de opmaak van al je variance cards en hoef je een aanpassing maar één keer te doen.
2. Periodevergelijkingen
In negen van de tien rapporten worden periodevergelijkingen gemaakt. De ene keer vergelijk je parameter X (bv. sales) over jaren, de andere keer over kwartalen of maanden. En de ene keer wil je het absolute verschil weten; de andere keer het procentuele verschil. Als je er lol aan hebt, kun je daar per geval een vergelijkbare, maar vrij complexe DAX measure voor schrijven, met risico op inconsistentie en meer beheer op de koop toe. Maar je kunt het ook af met één UDF met alle complexiteit, die je steeds opnieuw gebruikt, maar waarbij je alleen eenvoudigweg de gewenste periodevergelijking (Jaar, Kwartaal, maand) en berekening (absoluut, procentueel) ingeeft als tekst.
Als je dit zo leest, doen UDF’s je dan ergens aan denken? Mij wel. In eerste instantie associeerde ik ze even met calculation groups en items. Maar bij nader inzien verschillen ze toch echt van elkaar. Calculation groups gaan uit van bestaande measures en zorgen dat daar altijd dezelfde transformatie op wordt toegepast, zonder de measure zelf te wijzigen. Denk aan calculation items voor time intelligence of valuta-omrekening.
UDF’s bevatten herbruikbare logica die je expliciet aanroept in nieuwe measures, met door jou te bepalen parameters.
Kortom: calculation items pas je toe op bestaande measures, UDF’s roep je aan vanuit nieuwe. Ze sluiten elkaar dus niet uit, maar kunnen elkaar aanvullen.
Hoe werken UDF's?
Als je UDFs als preview functie hebt ingeschakeld, kun je van de kant. Idealiter bouw je ze op in de DAX Query View in Power BI Desktop:
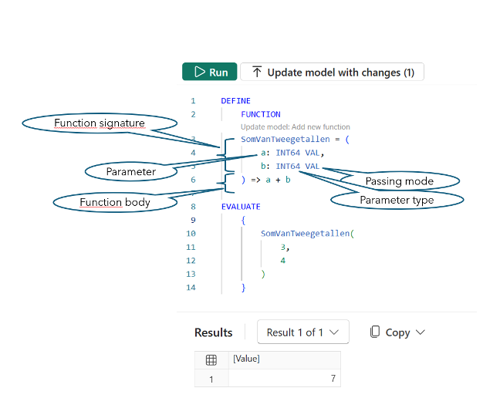
- Zoals gebruikelijk in DAX Query View, begint je code met: DEFINE.
- Vervolgens schrijf je de nieuwe ‘FUNCTION -functie’ en volgt de function signature, bestaande uit:functienaam (SomVanTweeGetallen) en parameter(s) (a, b), eventueel aangevuld met het type (INT 64) en de mode (VAL), gescheiden door een dubbele punt.
- In de function body schrijf je, beginnend met het teken => , wat jouw functie precies moet doen (a + b).
- Als je in query view resultaat wil terugzien in een tabel, voeg je een EVALUATE toe. Omdat de uitkomst een scalar is, waar in query view een tabel wordt verwacht, verpak je deze in accolades.
- ‘Run’ toont je het resultaat
- Zodra je het model 'update met modelwijzigingen,' komt de UDF beschikbaar in je datamodel en kun je 'm gebruiken in je measures

Parameter mode
Interessanter wordt het bij de parameter mode. En ook wel opletten geblazen. Er zijn twee smaken: VAL, wat staat voor VALUE en EXPR, wat staat voor EXPRESSION. Eerst de theorie.
VAL Jouw parameter wordt geëvalueerd vóórdat de functie wordt geëvalueerd. Net als bij een variabele (VAR) in DAX. Die parameter heeft dus altijd één vaste waarde, wat dus ook wil zeggen dat als deze parameter binnen een functie meerdere keren wordt aangeroepen, toch steeds hetzelfde resultaat heeft.
Als je deze eerdere UDF:

aanroept met de som van de sales prijs en de som van de sales quantity als argumenten / parameters,

dan wordt onder de motorkap, dit gedaan:

VAL is de default instelling. Als je de parameter mode niet nader specificeert, wordt de parameter op bovenstaande manier behandeld.
EXPR → De parameters worden níet vooraf geëvalueerd, maar behandeld als formules. Ze worden pas geëvalueerd wanneer de functie ze aanroept; Binnen de, ja hoor, daar is ie, actieve filtercontext. Wordt de parameter in jouw functie meerdere keren aangeroepen, dan kan het resultaat telkens verschillen. Dit is wat er dan onder de kap gebeurt:
![]()
VAL vs. EXPR: de filtercontext-valkuil
Ok, maar wat maakt dat nou uit? Goeie vraag. Nu de praktijk. Een makkelijk voorbeeld voor het begrip en een wat complexer, maar realistischer voorbeeld.
Met deze UDF kun je voor verschillende parameters (bijvoorbeeld sales amount, sales quantity, sales costs) de cijfers voor rode producten berekenen.

Als je vervolgens als parameter [Sales amount] ingeeft en een query schrijft voor een tabel met producten, sales en rode sales (EVALUATE)

krijg je dit, op het eerste oog verrassende resultaat:

Maar hoe kan de sales van rode producten nu hetzelfde zijn als voor alle producten? Dit is wat er gebeurt: De parameter mode is niet expliciet gemaakt, dus wordt automatisch VAL. Wat houdt dat ook alweer in? Dat de parameter wordt berekend vóórdat de functie wordt uitgevoerd. Die waarde staat dan vast; CALCULATE kan hem dus niet meer beïnvloeden. Er wordt wel gepoogd om de filtercontext aan te passen, maar er is geen formule [Sales Amount] om mee te rekenen: Je krijgt dus totaalwaarde terug, niet de gefilterde waarde.
Drie keer raden wat er gebeurt als je de parameter mode aanpast naar EXPR:

Ta-da, nu is de uitkomst ineens wél aannemelijk:

Hoe ik zelf probeer het verschil tussen VAL en EXPR te onthouden, is met een rode-appel-analogie:
Stel, je krijgt de opdracht: "tel de rode appels."
- VAL: Je loopt meteen naar medewerker van de fruitafdeling en vraagt hem hoeveel appels er zijn. Hij had ze allemaal al geteld; niet alleen de rode, en zegt: 100. Dus dát schrijf je op je briefje.
Je loopt naar het schap en ziet daar rode en groene appels liggen. Hoeveel er precies rood zijn? Nou, de telling is al gedaan. Hoeveel waren het er ook al weer volgens telling? 100. Dat staat er immers toch echt. - EXPR: Je loopt naar het schap en telt daar ter plekke alleen de rode appels. Uitkomst: 23.
VAL vs. EXPR: een praktijkvoorbeeld
Nog een voorbeeld. Grote kans dat je de ‘beste klanten’ van je opdrachtgever inzichtelijk hebt moeten maken. In dit voorbeeld, willen we toevallig de beste klant in termen van de omzet weten, maar het kan natuurlijk goed zijn dat je de beste klant definieert als de klant die het vaakst een aankoop doet, de meeste producten koopt et cetera. Typisch zo’n voorbeeld van een scenario dat je het gemakkelijkst met een UDF oplost. De parameter bepaalt in welk opzicht iemand ‘de beste klant’ is, de rest van de functie borgt dat verder steeds dezelfde DAX logica wordt toegepast.
Kijk eens naar onderstaande UDF, beloof jezelf plechtig dat je niet naar beneden scrolt voor de uitkomst en waag je eens aan een voorspelling van de uitkomst?
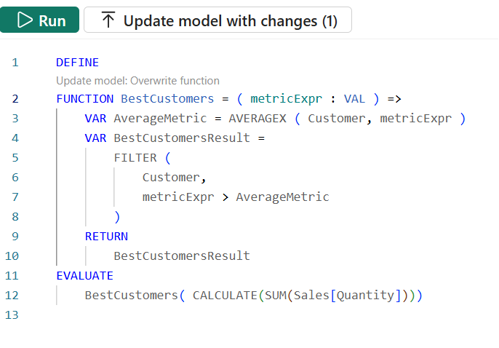
En? Inderdaad; in één keer goed! De uitkomst is... een lege tabel.
Waarom? De sales amount wordt vooraf berekend als variabele. Stel dat die € 350,- is. De averagemetric zegt: itereer over de customer tabel, geef me per klant de salesamount en retourneer onder aan de streep het gemiddelde daarvan. Voor iedere klant is de uitkomst hetzelfde: € 350. En het gemiddelde van € 350 is… Precies: € 350. De BestCustomerResult Variabele verzoekt om uitsluitend rijen terug te geven waarbij de parameter (€ 350) groter is dan het gemiddelde (€ 350); wat precies nul keer het geval is.
Als we VAL vervangen door EXPR is dit het resultaat:

De uitkomst van de MetricEXPR parameter is geen vaste waarde, maar verschilt per context omdat deze elke keer dat ie wordt aangeroepen opnieuw wordt berekend. Binnen AverageX verschilt de salesamount per klant. AverageX itereert over de klantdimensie, vindt voor klant A 2 rijen met sales in de sales-feitentabel en telt deze op tot 150. Voor klant B vindt AverageX drie rijen die optellen tot 200. Vervolgens komt daar een ander gemiddelde uit (175);
|
|
Sales |
Sales Amount |
|
Klant A |
100 + 50 |
150 |
|
Klant B |
125 + 50 + 25 |
200 |
|
|
|
(150 + 200) / 2 = 175 |
Binnen FILTER wordt afgedwongen dat alleen de rijen overblijven waarvoor de sales amount per klant groter is dan dat gemiddelde:
Klant A: 150 > 175? ❌ → valt af
Klant B: 200 > 175? ✅ → behoort tot beste klanten
Waarom VAL de standaard is?
In de meeste gevallen zal jouw UDF voor zijn parameter alleen een vaste waarde nodig hebben. De uitkomst is voorspelbaar en, zoals je je vast kunt voorstellen, sneller dan EXPR. Want als een parameter in jouw functie meerdere keren wordt ‘aangeroepen’, moet hij ook meerdere keren worden berekend. Bij grote datasets wordt dat al snel hard werken. Vandaar dat VAL dus de ‘default’ instelling is en je EXPR heel bewust moet kiezen, in die situaties waarbij je juist wil dat de filtercontext bepalend is voor de uitkomst.
Tot slot
UDF’s kunnen jouw leven als Power BI ontwikkelaar een stuk gemakkelijker maken. Less is more: Minder van (zo goed als) dezelfde measures. Minder beheer. Zeker met veelgebruikte measures die op het web tot je beschikking staan, kun je snel veel waarde toevoegen. Ik ga ze dan ook zeker gebruiken. En jij?
Dit artikel is mede gebaseerd op Isabelle Bittar – 10 Must-Have UDFs (Medium) en Marco Russo & Alberto Ferrari – Introducing user-defined functions in DAX (SQLBI).

