Datamigratie en hoe je dit goed kan voorbereiden
Datamigratie; data overbrengen van het ene systeem naar het andere. Klinkt vrij rechttoe rechtaan toch? Ok, je gaat natuurlijk niet zelf alle gegevens overtypen van systeem A naar systeem B. Dat wil je automatiseren. Dus daar wil je een tool voor hebben. Oh en systeem A met zijn data staat nog op een server op kantoor en tja, systeem B wordt in de Cloud gehost. Dus dat moet de tool wel ondersteunen. En past alle data van systeem A wel in systeem B? Niet qua grootte maar qua types?...en..en..
Je merkt het al, een data migratie project gaat niet over één nacht ijs. Dat vereist een goede voorbereiding. Wil je weten waar je dan allemaal aan moet denken? Lees dan verder, in deze blog leg ik uit hoe ik dat voor een klant heb aangepakt.
Over het algemeen zie je dat er voor elk datamigratieproject een aantal standaardprincipes gelden. Verderop in de blog zal ik uiteenzetten hoe Creates in samenwerking met de klant een datamigratieproject heeft uitgevoerd van verschillende on-premise systemen naar het in de Azure Cloud gelegen Microsoft Common Data Service.
SITUATIESCHETS
Zoals ik al eerder aangaf heb ik samen met een collega en in samenwerking met een klant in 6 maanden tijd het merendeel van de programmatuur voor de data migratie in de Azure Cloud gebouwd, getest en in een productieomgeving uitgevoerd.
Het migratietraject was onderdeel van een groter project waarin verschillende softwaresystemen (o.a. CRM, Financieel) op den duur vervangen zouden worden door het Microsoft Common Data Service. Dit om een hoge mate van standaardisatie, beveiliging, onderhouds- en gebruikersgemak te realiseren.
Ik zal je zonder al te veel in de details te treden schetsen
- welke data migratieprincipes gehanteerd zijn,
- welke technische architectuur en Azure Cloud componenten gebruikt zijn, waarom hier voor gekozen is en
- welke uitdagingen dit met zich meebracht.
ARCHITECTUUR
Data moet van systeem A naar systeem B. In het geval van deze klantcase moest er data van verschillende bronnen naar systeem B (het Microsoft Common Data Service). En de data uit deze bronnen moest opgesplitst worden over verschillende entiteiten in het Microsoft Common Data Service (het Microsoft Common Data Service bestaat uit een groot aantal standaard entiteiten die gebruikt kunnen worden om data uit applicaties bijv. Microsoft Dynamics365, in op te slaan). Qua architectuur zag het er zo uit:
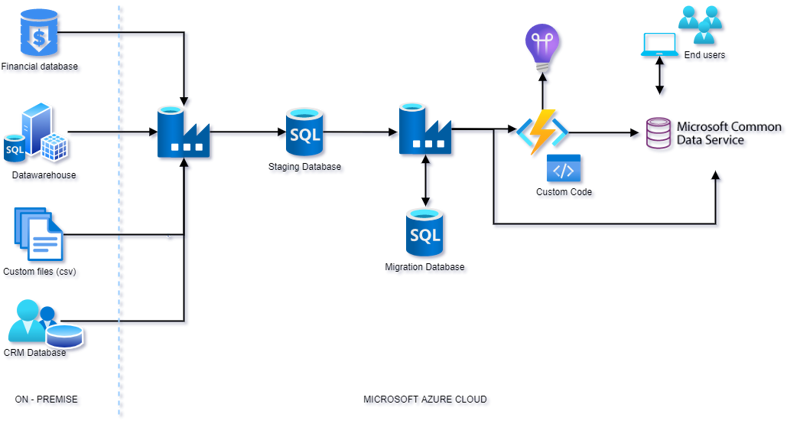
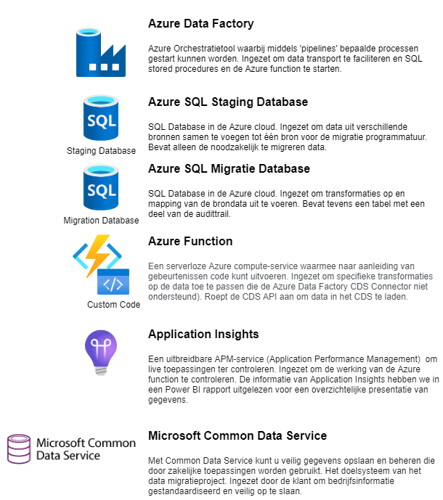
PRINCIPES
Doelsysteem leidend
Om te bepalen welke data uit de bronnen gemigreerd moest worden is het doelsysteem met zijn modules leidend gesteld.Er is door de klant een datamodel opgesteld waarin de doelentiteiten met de betreffende velden zijn gedefinieerd. Echter was dit model bij aanvang van het datamigratieproject nog niet definitief. Het resultaat was dat we op een ‘bewegend doel’ aan het schieten waren. De mapping die we opgesteld hadden veranderde op wekelijkse basis, waardoor wij regelmatig achter de feiten aanliepen. Om deze situatie in het vervolg te voorkomen hebben we afgesproken dat de mapping pas opgesteld word wanneer het datamodel van een entiteit definitief is.
Tevens hebben we afgesproken dat we niet meer migreren dan strikt noodzakelijk. Hierdoor word performance beter gewaarborgd (minder data is minder doorlooptijd tijdens het migreren van data) en word focus gehouden op data die ook daadwerkelijk gebruikt wordt in het doelsysteem.
Garbage in = garbage out
Tenminste, dat was in het begin zo afgesproken. Gebruikers van het Microsoft Common Data Service zouden de data achteraf corrigeren. En toch ontkwamen wij er niet aan om bepaalde dataschoningsacties uit te voeren alvorens de data in het Microsoft Common Data Service geladen zou worden. Op het Microsoft Common Data Service rustten namelijk bepaalde controles, als de data niet door deze controles heen zou komen zouden er noodzakelijke records uitvallen. De data in de bronsystemen corrigeren was niet altijd meer mogelijk.
Migratieproces automatiseren
Het migratieproces zou maar één keer in productie gaan plaatsvinden. Toch moest het proces en de programmatuur zodanig zijn ingericht dat het herhaalbaar uitgevoerd kon worden. Er zouden namelijk meerdere testruns uitgevoerd worden op de Ontwikkel- en Acceptatieomgeving. Idealiter wil je zo min mogelijk handmatige acties in het proces om controles en audittrails niet te onderbreken.
Nu voorziet de Azure Data Factory via triggers in het op gezette tijden starten van bepaalde processen. Maar omdat we (vanwege verschillende redenen) niet precies van te voren inzichtelijk hadden wanneer een testrun zou plaatsvinden hebben we ervoor gekozen om de testruns handmatig te starten.
Audittrails
Controle, controle, controle. Hoeveel records zijn er ingelezen uit de bron? Hoeveel records zijn er weggeschreven in het doelsysteem, per entiteit? Hoeveel records zijn er uitgevallen? Kloppen de totaalhoeveelheden (aantal stuks of bedragen) over alle records in de bron en het Microsoft Common Data Service na migratie? Maak een hashtotaal aan over alle records per entiteit en vergelijk deze tussen de bron en het doel. Een aantal methoden om er voor te zorgen dat je volledig bent in het proces van data overdracht.
Wij hebben voor de tellingen gekozen. Tijdens het laden werden deze tellingen in de ‘Migration database’ bijgehouden en vergeleken met de tellingen in het CDS. Tevens controleerden wij totaalbedragen tussen de bronsystemen en het CDS per entiteit. Dit alles samengesteld in Excelrapportages.
Testen is key
Om mogelijke kostbare fouten in de programmatuur in een zo vroeg mogelijk stadium van het project te detecteren zijn goede ontwikkeltesten van levensbelang. Onderlinge afhankelijkheid tussen componenten worden afgevangen in keten- en acceptatietesten. Wij hebben meerdere acceptatietesten uitgevoerd nadat de programmatuur succesvol door de ontwikkeltest gekomen was.
Uit de acceptatie- en performancetesten hebben wij een hoop geleerd. Waaronder waar bepaalde performance bottlenecks lagen en welke data nog een verbeterslag (lees: op datatype, - formaat en veldlengte) nodig had.
Wees flexibel
Met andere woorden, werk volgens een agile aanpak. Ik heb eerder al vermeld dat wij op een bewegend doel aan het schieten waren. Het datamodel van het doelsysteem was immers nog in ontwikkeling. Om hiermee om te gaan hebben we ons eerst gericht op het ontwikkelen van migratieprogrammatuur voor de entiteiten die wel definitief waren.
En anders waren wij wel druk met testen en uitzoeken van performanceproblemen.
Wij bleven continu in beweging.
CONCLUSIE
Ik hoop dat het duidelijk is geworden dat data migratie een project(onderdeel) is wat niet onderschat moet worden. En dat je een beter beeld hebt gekregen van wat er bij komt kijken.
Plan de nodige tijd en bereid je goed voor om een datamigratieproject zo succesvol mogelijk te laten verlopen, denk hierbij aan de volgende punten:
- Zorg dat de data mapping tussen het bron- en doelsysteem zo volledig mogelijk is voordat het project start.
- Maak afspraken over de datakwaliteit en waar deze gewaarborgd gaat worden.
- Automatiseer zo veel mogelijk handelingen in het migratieproces. Voorkom manuele fouten.
- Integreer audittrails in het migratieproces. Dit vereenvoudigd ook het opsporen van eventuele fouten in de programmatuur.
- Voer zo veel mogelijk testruns uit van het complete migratieproces. En voor livegang minimaal één keer met de volledige dataset. Zie dit als de generale repetitie voor de programmatuur en de gehele projectorganisatie.
- Wees flexibel. Ga niet wachten op anderen. Is het echt zo belangrijk dat die 10 records 1 dag voor de livegang nog foutloos gemigreerd worden in een testrun? Of kunnen ze na livegang ook nog handmatig aangepast worden in het doelsysteem? Denk hier over na en maak een overwogen beslissing.
Deze blog is niet allesomvattend omtrent datamigratie, mocht je nog vragen of hulp nodig hebben, verlegen zitten om een koffiepraatje omtrent een (komend) datamigratie traject in jouw organisatie? Neem dan vooral contact op, niels.laan@creates.nl.
Naslag
Microsoft Common Data Service: https://docs.microsoft.com/nl-nl/powerapps/maker/common-data-service/data-platform-intro

